
JavaScript DOM

DOM简介:
通过 HTML DOM,JavaScript 能够访问和改变 HTML 文档的所有元素。
HTML DOM(文档对象模型)
当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model)。
HTML DOM 模型被结构化为对象树:
对象的 HTML DOM 树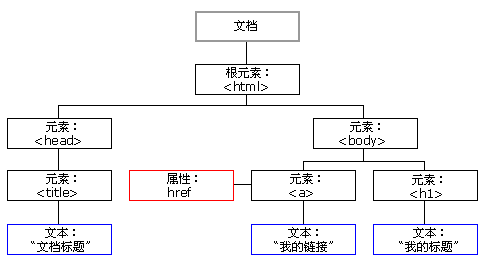
通过这个对象模型,JavaScript 获得创建动态 HTML 的所有力量:
- JavaScript 能改变页面中的所有 HTML 元素
- JavaScript 能改变页面中的所有 HTML 属性
- JavaScript 能改变页面中的所有 CSS 样式
- JavaScript 能删除已有的 HTML 元素和属性
- JavaScript 能添加新的 HTML 元素和属性
- JavaScript 能对页面中所有已有的 HTML 事件作出反应
- JavaScript 能在页面中创建新的 HTML 事件
什么是 DOM?
DOM 是一项 W3C (World Wide Web Consortium) 标准。
DOM 定义了访问文档的标准:
“W3C 文档对象模型(DOM)是中立于平台和语言的接口,它允许程序和脚本动态地访问、更新文档的内容、结构和样式。”
W3C DOM 标准被分为 3 个不同的部分:
- Core DOM - 所有文档类型的标准模型
- XML DOM - XML 文档的标准模型
- HTML DOM - HTML 文档的标准模型
什么是 HTML DOM?
HTML DOM 是 HTML 的标准对象模型和编程接口。它定义了:
作为对象的 HTML 元素
- 所有 HTML 元素的属性
- 访问所有 HTML 元素的方法
- 所有 HTML 元素的事件
换言之:HTML DOM 是关于如何获取、更改、添加或删除 HTML 元素的标准。
HTML DOM 是关于如何获取、更改、添加或删除 HTML 元素的标准。
Document对象是我们可以从脚本中对HTML页面中的所有元素进行访问
节点:Node——构成HTML文档最基本的单元。
常用节点分为4类:
- 文档节点:整个HTML文档
- 元素节点:HTML文档中的HTML标签
- 属性节点:元素的属性
- 文本节点:HTML标签中的文本内容

文档的加载:
浏览器在加载一个页面的时候,是按照自上向下的顺序加载的
读取到一行就运行一行,如果将script标签写到页面的上边,
在代码执行时,页面还没有加载,页面没有加载DOM对象也没有加载
会导致无法获取到DOM对象
Onload事件在整个 页面加载完成之后才触发
为window绑定一个onload事件
该事件对应的响应函数,将会在页面加载完成之后执行,
这样可以确保我们的代码执行时所有的DOM对象已经加载完成。
获取元素节点
通过document对象调用
1.getElementById()
通过id属性来获取一个元素节点的对象
2.getElementsByTagName()
可以根据标签名来获取一组元素节点对象
这个方法会给我们返回一个类数组对象,所有查询到的元素都会在封装到对象
即使查询到的元素只有一个,也会封装到数组中返回。
3.getElementsByName()
通过name属性来获取一组元素节点对象。
这个方法会给我们返回一个类数组对象,所有查询到的元素都会在封装到对象。
即使查询到的元素只有一个,也会封装到数组中返回。
InnerHTML 通过这个属性可以获取到元素内部的html代码
Bj.innerHTML
对于自结束标签没有意义,会返回为空。
如果需要读取元素节点属性,
直接使用 元素.属性名
例子: 元素.id 元素.name 元素.value
注意:class属性不能采用这种方式,(主要用于表单中)
读取class属性需要使用 元素. className
innerText
该属性可以获取元素内部中的文本内容。
他和innerHTML类似,不同的是他会自动将html标签去除。
获取元素节点的子节点
通过具体的元素节点调用
1.getElementByTagName()
是一个方法,方法返回当前的指定标签名后代节点
2.childNodes
是一个属性 表示当前节点的所有子节点
childNodes属性会获取包括文本节点在内的所有节点
根据DOM标签与标签间的空白也会当成文本节点
注意:IE8及以下的浏览器中不会将空白文本当成子节点,
children属性可以获取当前元素的所有子元素。标签与标签间的空白不会当成文本节点。
3.firstChild
属性,表示当前节点的第一个子节点。
可以获取当前元素的第一个子节点(包含空白文本节点和注释)。
firstElementChild:指向第一个元素;(不包括文本节点和注释)
4.lastChile
属性,表示当前节点的最后一个子节点
可以获取当前元素的最后一个子节点(包含空白文本节点和注释)。
lastElementChild:指向最后一个子元素;(不包括文本节点和注释)
遍历元素
childElementCount:返回子元素的个数(不包括文本节点和注释)
获取父节点和兄弟节点
通过具体的节点调用
1.parentNode
属性,表示当前节点的父节点
2.previousSibling
属性,表示当前节点的前一个兄弟节点
previousSibling 属性返回元素节点之前的兄弟节点(包括文本节点、注释节点);
previousElementSibling 属性只返回元素节点之前的兄弟元素节点(不包括文本节点、注释节点);
3.nextSibling
属性,表示当前节点的后一个兄弟节点
nextSibling 属性返回元素节点之后的兄弟节点(包括文本节点、注释节点);
nextElementSibling 属性只返回元素节点之后的兄弟元素节点(不包括文本节点、注释节点)。
1、在document中有一个属性body,它保存的是body的引用
Var body = document.body;
2、Doucument.doucumentElement保存的是html根标签
Var html = document.documentElenmet;
3、Document.all 代表页面中的所有元素
var all = document.all;
(var all = document.getElementsByTagName(“*”))效果一样。
它返回一个数组
4、根据元素的class属性查询一组元素节点对象
GetElementsByClassNmae() 可以根据class属性值获取一组元素节点对象(类数组)
但是该方法 不支持IE8及以下浏览器。
5、documen.querySelector()
需要一个选择器的字符串作为参数,可以根据一个CSS选择器来查询一个元素节点对象
虽然IE8中没有getElementByTagName() 但是可以使用querySelector,他可以支持IE8.
使用该方法总会返回一个唯一的一个元素,如果满足条件的元素有多个,那么它会返回第一个。
6、documen.querySelectorAll()
该方法和querySelector()用法类似,不同的是他会将符合条件的元素封装到一个数组中。
即使符合条件的元素只有一个,他也会返回数组。
DOM增删改查:
1.Document.createElement()
可以用于创建一个元素节点对象,
它需要一个标签名作为参数,将会根据标签名创建元素节点对象
并将创建好的对象作为返回值返回。
它可以个innerHTML结合使用。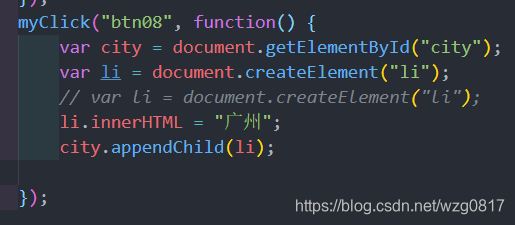
2.document.createTextNode()
可以用来创建一个文本节点对象
需要一个文本内容作为参数,将会根据该内容创建文本节点,并将新的节点返回。
3.appendChild()
向一个父节点中添加一个新的子节点
用法:父节点.appendChild(子节点);
4.insertBefore()
可以在指定的子节点前插入新的子节点
语法:
父节点.insertBefore(新节点,旧节点);
5.replaceChild()
可以使用指定的子节点替换已有的子节点
语法:
父节点.replaceChile(新节点,旧节点)
6.removeChild()
可以删除一个子节点
语法:父节点.removeChild(子节点);
但是:
常用:子节点.parentNode.removeChild(子节点)
Document 对象
每个载入浏览器的 HTML 文档都会成为 Document 对象。
Document 对象使我们可以从脚本中对 HTML 页面中的所有元素进行访问。
提示:Document 对象是 Window 对象的一部分,可通过 window.document 属性对其进行访问。
一、文档子节点
1、在document中有一个属性body,它保存的是body的引用(比通过childNodes列表访问的更快,更直接)
Var body = document.body;
2、Doucument.doucumentElement保存的是html根标签
Var html = document.documentElenmet;
3、Document.all 代表页面中的所有元素
var all = document.all;
(var all = document.getElementsByTagName(“*”))效果一样。
它返回一个数组
4、根据元素的class属性查询一组元素节点对象
GetElementsByClassNmae() 可以根据class属性值获取一组元素节点对象(类数组)
但是该方法 不支持IE8及以下浏览器。
5、documen.querySelector()
需要一个选择器的字符串作为参数,可以根据一个CSS选择器来查询一个元素节点对象
虽然IE8中没有getElementByTagName() 但是可以使用querySelector,他可以支持IE8.
使用该方法总会返回一个唯一的一个元素,如果满足条件的元素有多个,那么它会返回第一个。
6、documen.querySelectorAll()
该方法和querySelector()用法类似,不同的是他会将符合条件的元素封装到一个数组中。
即使符合条件的元素只有一个,他也会返回数组。
二、文档信息
1.document.title
可以取得当前界面的标题,也可以修改当前界面的标题并反映给浏览器的标题栏中。
1 | console.log(document.title) //查看标题 |
2.属性 URL、domain、referrer 都和网页请求有关。
URL属性包含完整的URL
domain属性中只包含了页面的域名。
referrer属性中保存着连接到当前页面的哪个页面的URL,在没有来源页面的情况下,referrer属性中可能会包含空字符串
三、查找元素
1.getElementById()
通过id属性来获取一个元素节点的对象
2.getElementsByTagName()
可以根据标签名来获取一组元素节点对象
这个方法会给我们返回一个类数组对象,所有查询到的元素都会在封装到对象
即使查询到的元素只有一个,也会封装到数组中返回。
3.getElementsByName()
通过name属性来获取一组元素节点对象。
这个方法会给我们返回一个类数组对象,所有查询到的元素都会在封装到对象。
即使查询到的元素只有一个,也会封装到数组中返回。
四、特殊集合
1、document.anchors
包含文档中所有带name特性的 a 元素
2、document.forms
包含文档中所有的